| Model / Method | Base Model | MBPP | MBPP+ | HumanEval | HumanEval+ | LCB v6 | Avg. |
|---|---|---|---|---|---|---|---|
| Open-Sourced Models | |||||||
| Autoregressive Coding Models | |||||||
Qwen 2.5 Coder*autoregressive | Qwen2.5-7B | 75.9 | 62.9 | 66.5 | 60.4 | 26.8 | 59.9 |
OpenCoder*autoregressive | from scratch (8B) | 79.9 | 70.4 | 66.5 | 63.4 | 29.6 | 62 |
OlympicCoder*autoregressive | Qwen2.5-7B | 80 | 66.4 | 82.1 | 76.9 | 37.3 | 68.5 |
Seed-Coder*autoregressive | from scratch | 82 | 69 | 77.4 | 68.3 | 28.4 | 65 |
| Diffusion Language Models | |||||||
Dream*diffusion | Qwen2.5-7B | 68.7 | 57.4 | 56.7 | 50 | 18.6 | — |
LLaDA*diffusion | from scratch (8B) | 50.1 | 42.1 | 35.4 | 30.5 | 12.4 | — |
Diffu-Coder*diffusion | Qwen2.5-Coder-7B | 75.1 | 61.9 | 72 | 65.2 | 24.5 | 59.7 |
Dream-Coder*diffusion | Qwen2.5-Coder-7B | 75.9 | 61.6 | 66.5 | 60.4 | 21.4 | 57.2 |
d1*diffusion | LLaDA+RL | 39 | — | 45.5 | — | — | — |
| Looped Latent Reasoning Models | |||||||
Ouro*looped | from scratch (2.6B) | 80.4 | 66.6 | 78.2 | 70.7 | 38.7 | 66.9 |
| Method Comparison | |||||||
| Same Backbone Comparison (Qwen3-8B-Base) | |||||||
Base Model | Qwen3-8B-Base | 60.5 | 53.8 | 78.2 | 68.6 | 17.7 | 55.8 |
Standard SFT | Qwen3-8B-Base | 63.3+2.8 | 52.7-1.1 | 84.6+6.4 | 69.5+0.9 | — | — |
Soft Thinking | Qwen3-8B-Base | 64.2+3.7 | 53.1-0.7 | 85+6.8 | 71.2+2.6 | — | — |
TaH+ | Qwen3-8B-Base | 65.6+5.1 | 56.5+2.7 | 85.8+7.6 | 74.3+5.7 | — | — |
LaVAE | Qwen3-8B-Base | 42-18.5 | 30.2-23.6 | 47.8-30.4 | 32.8-35.8 | 10.8-6.9 | 32.7-23 |
LaDiRdiffusion | Qwen3-8B-Base | 66.8+6.3 | 59.5+5.7 | 87.4+9.2 | 73.2+4.6 | 21.3+3.6 | 61.6+5.9 |
NF-CoT (Dual-Path)normalizing flowOurs | Qwen3-8B-Base | 77.5+17 | 66.2+12.4 | 82.9+4.7 | 77.7+9.1 | 21.6+3.9 | 65.2+9.4 |
NF-CoT (Unified)normalizing flowOurs | Qwen3-8B-Base | 83.9+23.4 | 72.1+18.3 | 85.8+7.6 | 78.3+9.7 | 23.7+6 | 68.8+13 |
↳ + RLnormalizing flowOurs | Qwen3-8B-Base | 85.4+24.9 | 73.3+19.5 | 86.7+8.5 | 80.2+11.6 | 25.1+7.4 | 70.1+14.3 |
Pass@k Scaling
Pass@k measures the probability that at least one of k generated samples passes all test cases. NF-CoT's probabilistic sampling in continuous thought space enables diverse solution exploration, leading to consistent improvements over both the base model and LaDiR across all k values.
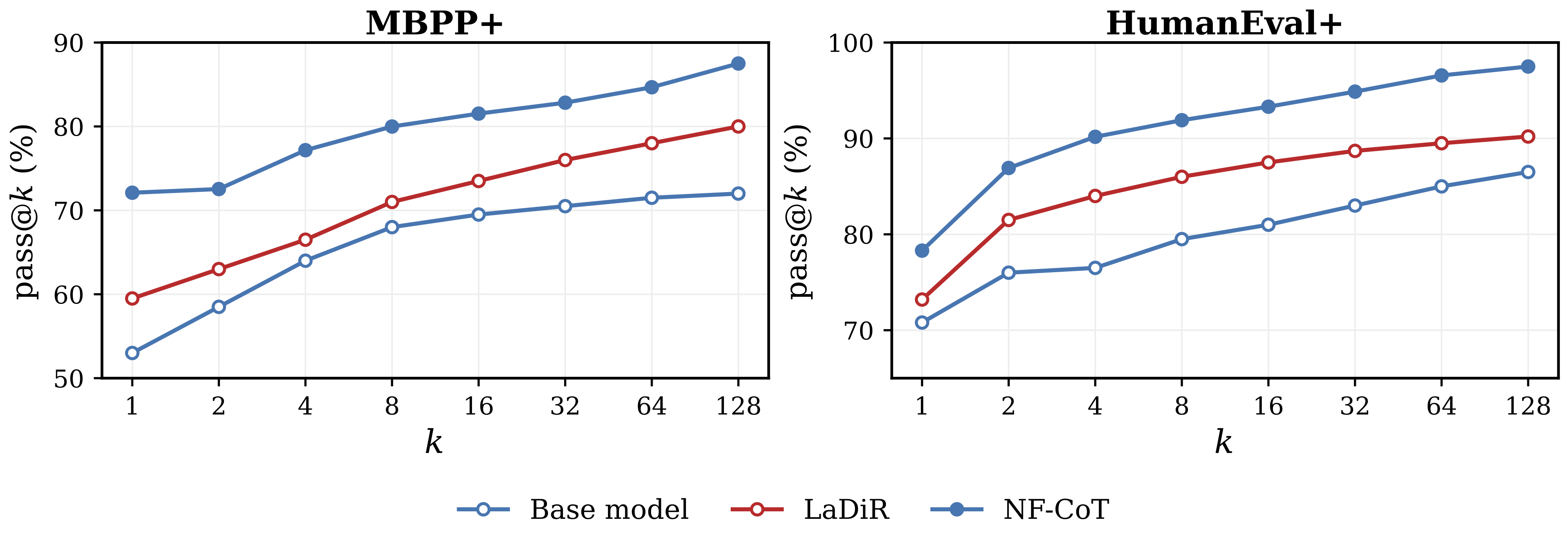
Figure 3: Pass@k on MBPP+ (left) and HumanEval+ (right). NF-CoT dominates both baselines across the full k range. On MBPP+, NF-CoT's pass@1 (72.1) already matches the base model's pass@128 (72.0) and rises to 87.5 at k = 128. On HumanEval+, NF-CoT improves from 78.3 to 97.5 (+19.2).
RL Preserves Pass@k Diversity
A common concern is that optimizing a single correctness reward with RL can raise pass@1 while collapsing the diversity needed for pass@k scaling. We compare standard token-space GRPO with our latent-space RL under the same pass@k diagnostic. Token-space GRPO improves the low-k region but saturates at larger k, while latent-space RL for NF-CoT improves pass@1 and preserves the upward scaling trend.
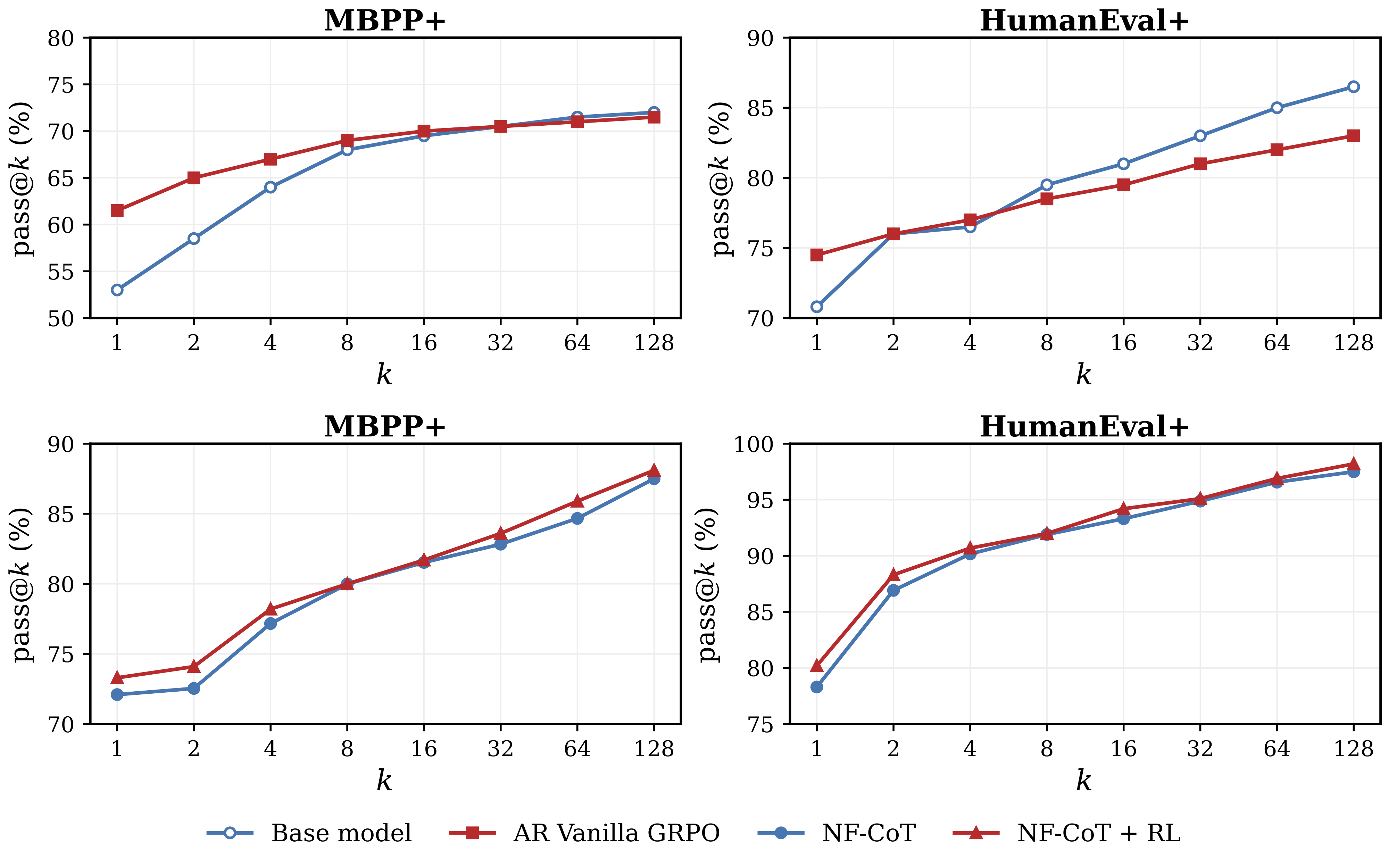
Figure 4: Pass@k diversity before and after RL. Top row: token-space GRPO concentrates probability mass on fewer solution modes and saturates below the base model at large k. Bottom row: policy-gradient refinement in the continuous-CoT space does not collapse the latent trajectory distribution, keeping NF-CoT + RL consistently above the supervised checkpoint across the full k range.